
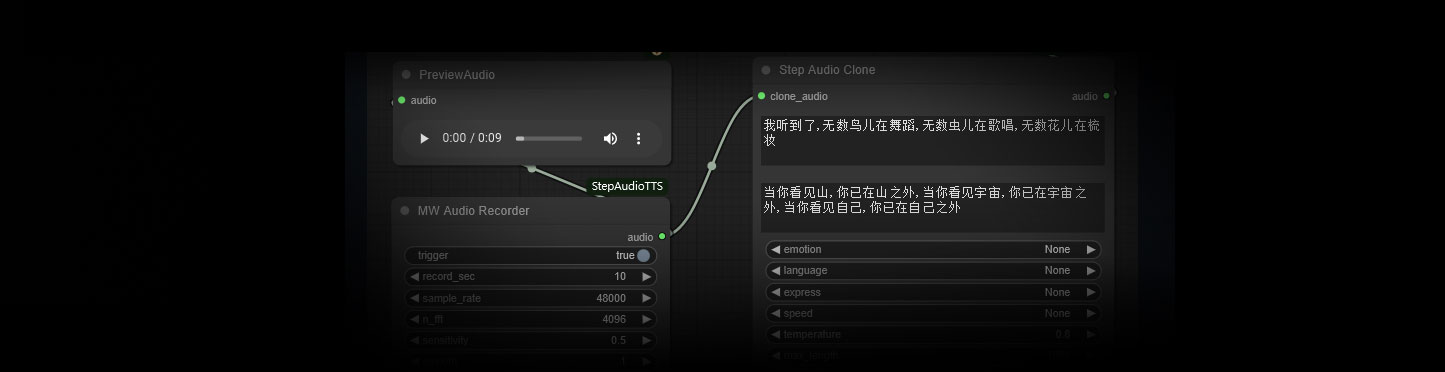

插件介绍
基于Step-Audio-TTS的ComfyUI文本到语音节点。可以说话,说唱,唱歌,或克隆声音。
安装方法
插件安装
插件解压后(去掉-main)放到ComfyUI根目录的custom_nodes路径下。.在文件夹上面输入cmd打开脚本编辑器并输入以下脚本(路径替换为你的ComfyUI Python环境路径):
F:\ComfyUI\python_embeded\python.exe -s -m pip install -r requirements.txt模型安装
1.在ComfyUI models路径下新建一个TTS的文件夹,将下面两个模型文件夹下载到该路径内。
2.将插件文件夹夹里的Step-Audio-speakers文件夹也复制到上面创建的路径里。最终需要放置的模型如下:
![图片[1]-ComfyUI_StepAudioTTS声音克隆插件-数字折叠](https://oss.digitfold.com/img/2025/04/20250426023633389.jpg)

提供远程协助
支持需求定制
适用软件ComfyUI
语言中英
大小5.63mb
工具使用问题请联系qq1990781688
免费资源
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END


















暂无评论内容